







Introduzione

Foto pubblicata da La Gazzetta di Mantova
I disastri naturali possono accadere in qualsiasi momento (questa immagine mostra il crollo del cupolino di un campanile accaduto a Mantova, una città a 5Km di distanza dagli uffici di Spazio IT, durante un piccolo terremoto nel mese di maggio 2012 in una zona che si pensava esente da ogni rischio sismico).
Blaise Pascal, un filosofo e scienziato francese del diciassettesimo secolo, ha scritto “L’uomo non è che una canna, la più fragile della natura, […]. L’universo intero non ha bisogno di armarsi per schiacciarlo: un vapore, una goccia d’acqua bastano per ucciderlo.”
In terminologia IT un data center (anche un cloud data center – espressione molto di moda oggi) può smettere di funzionare anche senza che accada un disastro naturale. Un problema di connettività, un incendio, qualche guasto nella distribuzione dell’energia, possono fare si che il data center non sia più disponibile.
Pascal continua così: “Ma quando l’universo lo ha schiacciato, l’uomo sarà ancora più nobile di ciò che lo uccide, perché sa di morire, mentre della sua vittoria l’universo non sa nulla.”
Traducendo ancora una volta in terminologia IT, abbiamo un cervello, abbiamo la possibilità di progettare architetture, configurazioni di sistemi che sono così robuste da resistere anche ai disastri naturali.
La chiave: Ridondanza
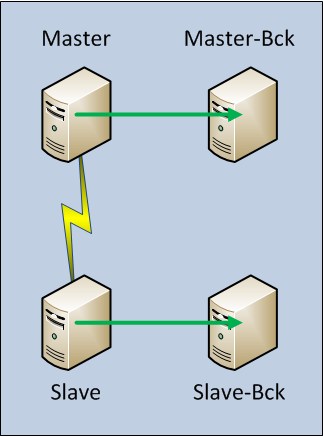
La chiave è molto semplice: Ridondanza: al posto di avere un solo sistema che gira in un solo data center, basta avere due sistemi differenti (uno la copia dell’altro) che girano in due data center diversi.
Questi due sistemi sono: il master system (usato in condizioni mormali) e lo slave system (usato quando il master non è disponibile).
Ognuno dei due sistemi è composto da una server machine e da una back-up machine (una macchina oppure un’area FTP/NFS al cui interno viene eseguita la back-up). La server machine e la back-up machine sono reciprocamente locali (si trovano cioè sulla stessa rete locale, nello stesso data center).
Requisiti logici e limiti fisici
Da un punto di vista logico:
- il master e lo slave dovrebbero essere l’uno il clone dell’altro (o il più possibile simili)
- più lontani il master e lo slave sono e più sicura e robusta è la configurazione risultante
ma
- più lontani il master e lo slave sono e più risulta difficile assicurare che i due sistemi siano identici ad un costo accettabile.
Se la connessione fra il master e lo slave è molto veloce (p.es. su fibra) è possibile eseguire un aggiornamento quasi real-time dei due sistemi. Se la connessione non è così veloce, in base alla quantità di dati che si devono scambiare, solo alcuni aggiornamenti al giorno risultano possibili.
Scenari di guasto ed inversione dei ruoli
- Lo slave system si guasta – il master funziona ancora. Se e quando lo slave system riprende a funzionare il meccanismo di aggiornamento automatico ne rinfrescherà i contenuti senza problemi particolari.
- Il master system si guasta – lo slave system funziona ancora (per quanto contenga dati coerenti con l’ultimo aggiornamento) e può essere utilizzato immediatamente. Se e quando il master system riprende a funzionare il meccanismo di auto aggiornamento deve essere fermato oppure si deve procedere all’inversione dei ruoli tra il master e lo slave. Se questo non accade il master system rischia di sovrascrivere i dati nuovi presenti nello slave system con i dati vecchi che aveva prima del guasto. L’interruzione dell’aggiornamento o l’inversione dei ruoli devono scattare automaticamente in caso di guasto del master system.
Un esempio concreto
Spazio IT ha realizzato per il Gruppo Trinità una Soluzione di Disaster Recovery con le seguenti caratteristiche:
- Master System
- Server Machine – una macchina virtuale KVM ospitata presso OVH (Strasburgo, Francia) con 4GB di RAM e 150GB di hard disk
- Backup Machine – un’area FTP anch’essa ospitata presso OVH
- Slave System
- Server Machine – una macchina virtuale VMware ospitata presso una delle sedi (a sud di Verona) del Gruppo Trinità con 4GB di RAM e 150GB di hard disk
- Backup Machine – un NAS piccolo ed economico locale alla server machine
- Update Rate – Tre volte al giorno (RPO: 8 ore, RTO: 0 ore – immediato)
- Connettività Master –> Slave – Media 70/80 Mbps – Minima 15 Mbps